STORIES

This blog is written by Gabie Boon, Data Engineer at Triple.
Hi, I am Gabie. In 2020, I started my graduation internship for HBO Informatica (University for Applied Computer Sciences) at Triple. After successfully completing the research, I graduated and entered Triple’s data team as a Data Engineer.
In this blog, I will tell you all about my Triple adventure, the development I went through and how I entered the world of data. Looking back, I see myself joining the company basically without any knowledge of data. And look at me now: I am fully capable of independently providing Triple’s partners with end-to-end data solutions!
The wonderful world of data
The team was relatively new, it had only just been formed. This provided me with the advantage and freedom to determine my own working methods. Because I knew so little about working with data, it made total sense that I spent most of my first weeks in this job studying. I will take you through what I learned.
Working with data is twofold: collecting the data (which is called data engineering) and visualizing the data (which is called data science). They are two separate disciplines, both of which I have started working with. I will tell you more about how I operate within these fields.
Preparing data for use: data engineering
All data is stored in a central location before it can be visualized. At Triple, we apply two methods for this: a data lake and a data warehouse. In a data lake, raw data is stored. This is mainly semi-structured data (CSV, logs, XML, JSON) and unstructured data (e-mails, PDF, documents) in large quantities. As we read out the data sources on a daily basis in the data lake, we are also able to build up a fair amount of history. A major advantage of storing data in a raw state is that at a later stage, it can be very useful for Artificial Intelligence. A data warehouse is a centralized place where transformed data is stored in a structured manner. In the data warehouse, links are indicated between the various data sources so that they can ultimately be visualized.
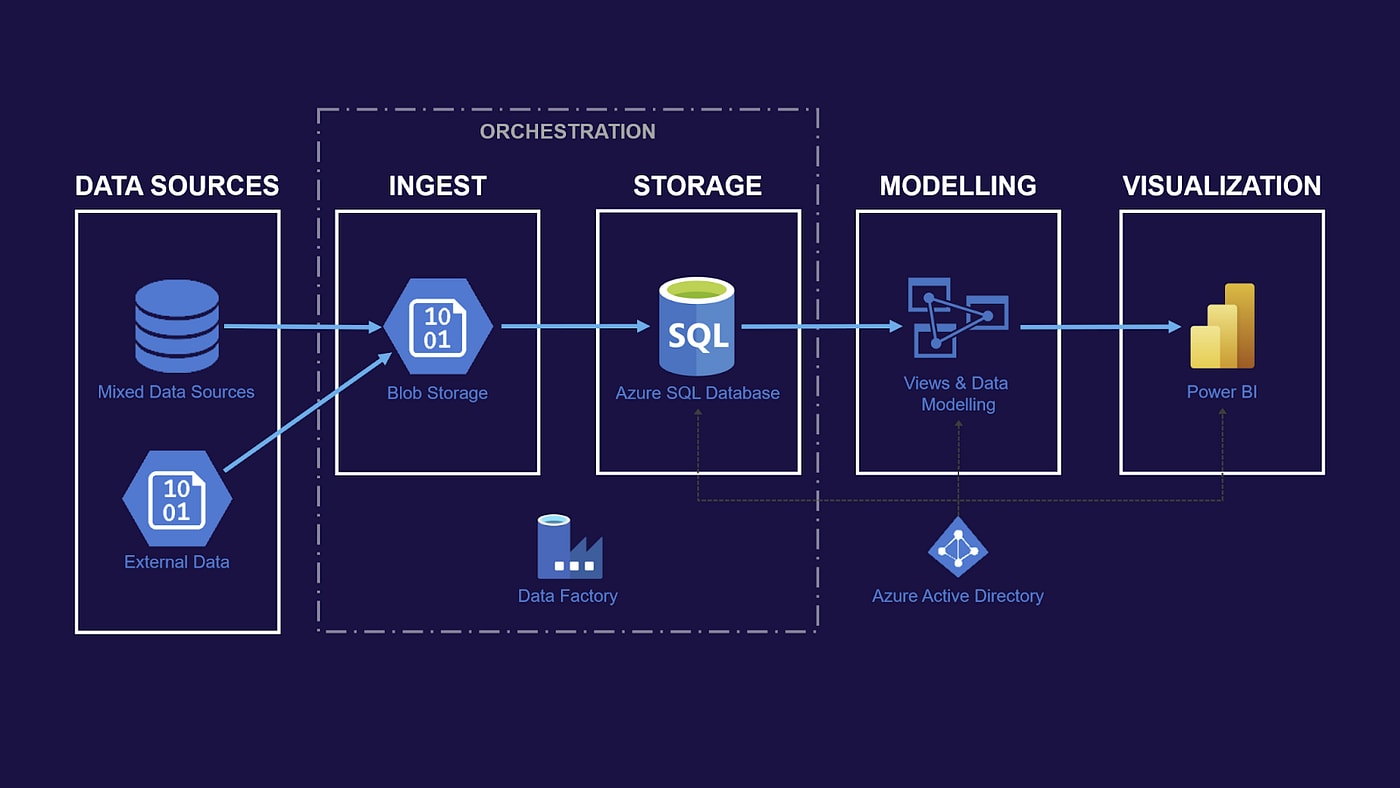
In the image above, you can see how the data engineering process works. We load data sources (APIs, databases and more) into the data lake with our own software. From there, we load a data model into the data warehouse. The data can be used straight from the data warehouse for the next step: visualizing the data, where we show (sometimes manually and sometimes automatically) the relationship between the data.
Data engineering can take place on different platforms. At Triple, we work mostly with Azure as a cloud solution. For some projects, we work in Google Cloud and AWS (Amazon).
Visualizing data: data science
We visualize data with various tools. Microsoft Power BI is our favorite because it has been included as a standard tool in the Office 365 license for years. Many organizations already have it at their disposal, the threshold to start using it is relatively low. Power BI is also an easy no/low-code solution for creating visualizations using drag and drop. The disadvantage of Power BI is that you are bound to a limited number of styling options.
If a need arises for a dashboard with additional styling options, we use Tableau, which is similar to Power BI. The main difference is that visualizations can be customized more extensively. Tableau also better supports the use of real-time dashboards.
In addition to these two classic dashboard tools, we also use an embedded dashboard tool. Sisense is a handy tool for our partners, it offers a custom-made web application. By using their APIs and SDKs we can build the visualizations into the desired application.
What is it like to be part of Triple’s data team?
At Triple, we offer complete end-to-end data solutions. I handle both the back-end (data engineering) and front-end (data science) and I particularly enjoy the combination. We start from the source and work our way up to the final product. It truly energizes me to please our partners with a usable end product. As a result of my work, they are then able to make important, business-critical choices!
Working at Triple is a huge learning experience for me. I have every opportunity to obtain certificates proving I am a proper data engineer. My first ambition is to now first learn how to get all the data in one place and how to visualize it in the most esthetical way. Next, I want to dive deeper into enriching data with AI.
Pizzas, hobby projects and get-togethers
Besides the cool projects and the learning experience, Triple is also a super cool organization to work for. We have all kinds of fun events. Every Tuesday we have Tropical Tuesday, during which we all have dinner together (such as pizza, Thai or spareribs) and work together on hobby projects with colleagues after work. Once a month, Triple hosts a big theme party, and it is great fun to enjoy a few drinks with my colleagues there.



Explore the Triple Universe
Learn more about Triple, our culture or check out our vacancies.
